menu
Generative landscape
Live demo: https://augmented-emotion.vercel.app/
Generative landscape based on sound frequency. Similar to a Spectrogram that shows how the spectrum of frequencies varies over time. The idea of this project was to explore audio based visuals. This could be an installation that shows a collection of these "scenes". Each visitor will generate their own audio signature and it will be displayed as part of a collection. To make the results more varied sentiment analysis is used to change the colors based on your mood, volume controls color intensity etc.
The connection is about feeling part of a community. People can make their own and compare and contrast with others' models. e.g. when other's models looks similar to yours in color, intensity etc. you can guess that they answered the question in a similar way.
Random Kanye interview for demonstration purposes, shows transition between colors.
Live demo
Process
This project started initially as a tool that would "loft" together audio FFT waves, which would result in something that would resemble a landscape. In the final experiment i chose to present it as a circle to mimic more traditional audio formats such as record players. It also makes it more "model" - like in the way that it's not just a bar of "mountains".
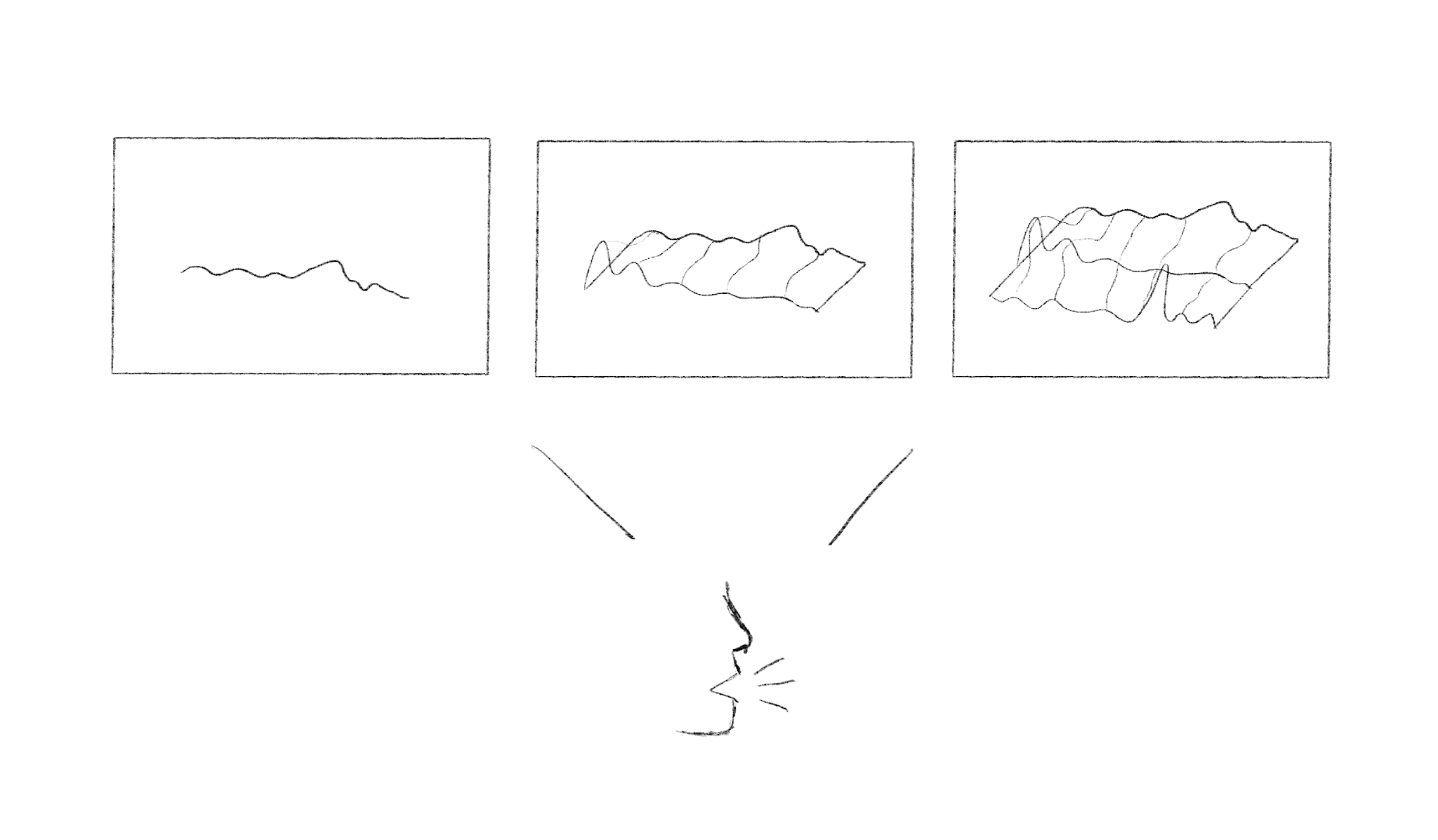
This is how it initially worked. Just tried to recreate the sketch. Every x seconds a copy is generated and animated in the z - direction. In the final project it's using a data texture on a flat plane instead, which is basically a texture made up of raw data. E.g. the FFT size controls the resolution of the texture / how many columns (low FFT results in more voxel - style displacement) and the height controls how long it will be / how many rows (how long the animation is). By offsetting each row of data every time the audio analyser updates, the displacement will be animated in the z - direction.
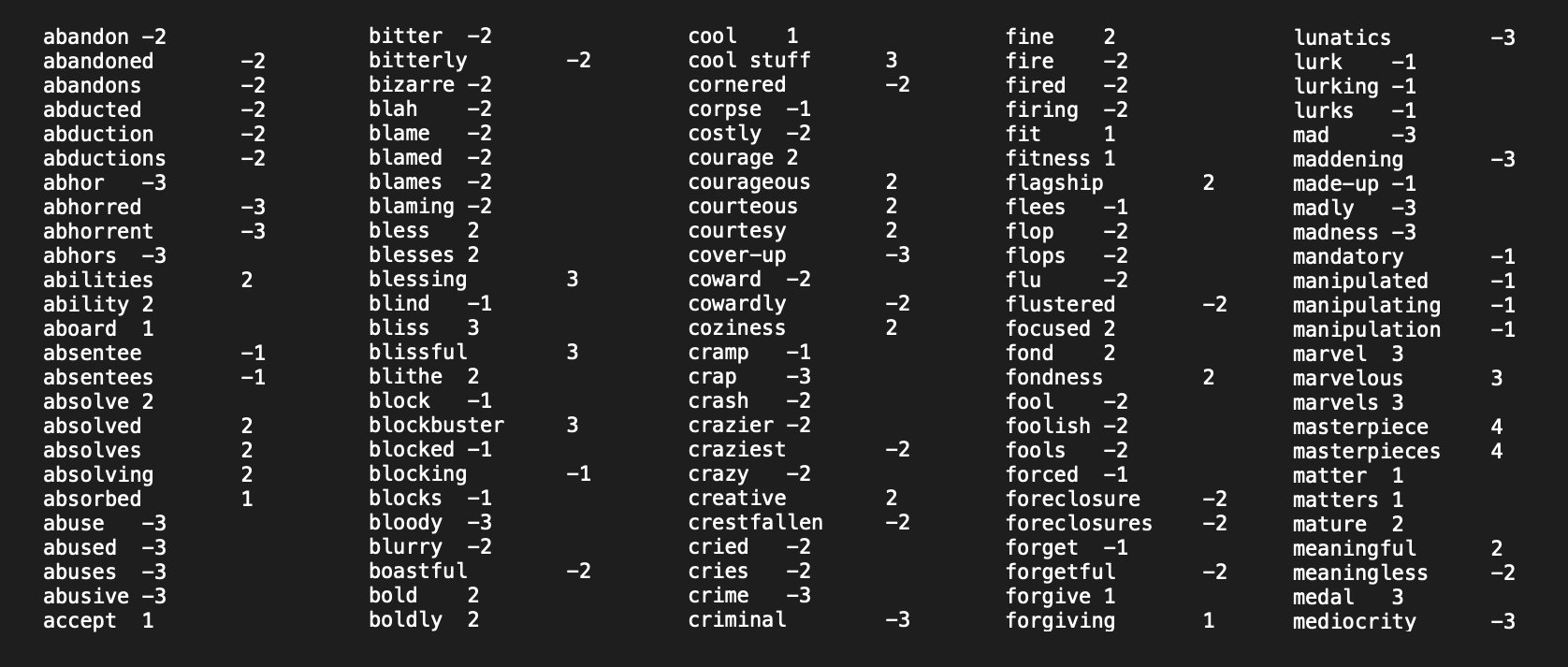
To analyse the sentiment / polarity of your speech it has to go through a few loopholes. There are APIs out there that can do this based on the tone of your voice etc. but as these cost money i tried to go about it another way. The AFINN dictionary is a set of words where each word has a corresponding score ranging from -5 to 5. By first using the web speech API, your speech is transcribed to text. Then each word from this transcription is checked in the AFINN dictionary where a score is calculated. This is by no means an accurate approach to analysing your emotions (only gives a sense of positivity / negativity), but for shorter intervals of text it gives ok results.
Of course having the polarity value shown is redundant as the color change is more than enough.
↩︎ previous project
next project